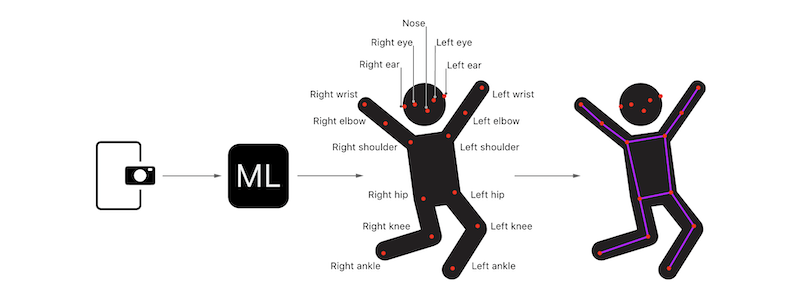
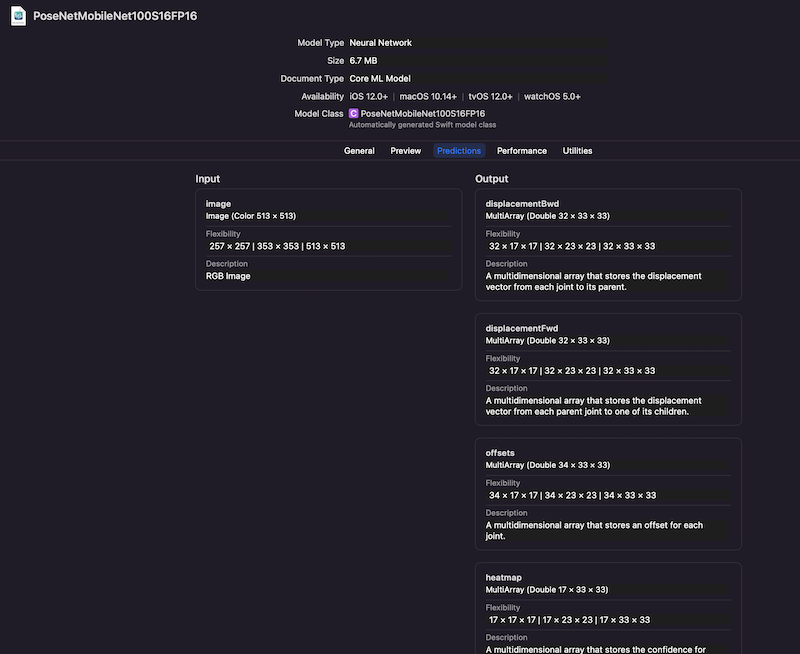
// 人体特征点类 classJoint{ // 特征点名字枚举,这里的顺序和模型多维数组中的顺序是一致的 enumName: Int, CaseIterable{ case nose case leftEye case rightEye case leftEar case rightEar case leftShoulder case rightShoulder case leftElbow case rightElbow case leftWrist case rightWrist case leftHip case rightHip case leftKnee case rightKnee case leftAnkle case rightAnkle } // 名字 let name: Name // 可信度 var confidence: Double // 所在图片上的位置 var position: CGPoint init(name: Name, position: CGPoint = .zero, confidence: Double = 0) { self.name = name self.position = position self.confidence = confidence } }
classPoseModel{ // 共17个特征点 let jointCount = 17 // 此模型会将图片分割成33*33的区块 let xBlocks = 33 let yBlicks = 33 // 所有特征组成的字典 var joints: [Joint.Name: Joint] = [ .nose: Joint(name: .nose), .leftEye: Joint(name: .leftEye), .leftEar: Joint(name: .leftEar), .leftShoulder: Joint(name: .leftShoulder), .leftElbow: Joint(name: .leftElbow), .leftWrist: Joint(name: .leftWrist), .leftHip: Joint(name: .leftHip), .leftKnee: Joint(name: .leftKnee), .leftAnkle: Joint(name: .leftAnkle), .rightEye: Joint(name: .rightEye), .rightEar: Joint(name: .rightEar), .rightShoulder: Joint(name: .rightShoulder), .rightElbow: Joint(name: .rightElbow), .rightWrist: Joint(name: .rightWrist), .rightHip: Joint(name: .rightHip), .rightKnee: Joint(name: .rightKnee), .rightAnkle: Joint(name: .rightAnkle) ] var data: PoseNetMobileNet100S16FP16Output // 每个区块的宽高 var blockWidth: Double var blockHeight: Double // 使用此输出模型来解析 init(data: PoseNetMobileNet100S16FP16Output, width: Double, height: Double) { self.data = data self.blockWidth = width self.blockHeight = height // 对每个节点进行解析 joints.values.forEach { joint in cofigure(joint: joint) } joints.values.forEach { joint in // 打印每个特征点的可信度 print(joint.name, joint.confidence) } } funccofigure(joint: Joint) { // 解析出可信度最高的block 记录可信度和区块位置 var bastConfidence = 0.0 var bastBlockX = 0 var bastBlockY = 0 for x in0 ..< xBlocks { for y in0 ..< yBlicks { let multiArrayIndex = [NSNumber(integerLiteral: joint.name.rawValue), NSNumber(integerLiteral: y), NSNumber(integerLiteral: x)] let confidence = data.heatmap[multiArrayIndex].doubleValue if confidence > bastConfidence { bastConfidence = confidence bastBlockX = x bastBlockY = y } } } joint.confidence = bastConfidence // 获取详细的坐标位置,offsets多维数组中存放的是对应特征点的偏移位置,前17个为y偏移,后17个为x偏移。 let yOffsetIndex = [NSNumber(integerLiteral: joint.name.rawValue), NSNumber(integerLiteral: bastBlockY), NSNumber(integerLiteral: bastBlockX)] let xOffsetIndex = [NSNumber(integerLiteral: joint.name.rawValue + jointCount), NSNumber(integerLiteral: bastBlockY), NSNumber(integerLiteral: bastBlockX)] let offsetX = data.offsets[xOffsetIndex].doubleValue let offsetY = data.offsets[yOffsetIndex].doubleValue // 通过偏移量加上区块的起始位置来确定最终位置 joint.position = CGPoint(x: Double(bastBlockX) * blockWidth + offsetX, y: Double(bastBlockY) * blockHeight + offsetY) } }